Amazon Elasticsearch Serviceを使ったログ収集基盤の構成を考えてみた
みなさんこんにちは。@ryuzeeです。 6月10日にAmazon Web Services企業導入ガイドブックが発売になっていますのでよろしくお願いします。
さて今回はAWS上でログ収集と分析をする際に、Amazon Elasticsearch Serviceを使う前提とした場合だとどのような構成案がありそうかいくつか考えてみたのでご紹介します。
なお、検討の材料にしている全体の構成としては、複数のVPC(またはAWSアカウント)があって、さらにオンプレ側とDirect ConnectやInternet VPNで接続しているような、よくあるそれなりの規模の構成になります。 各VPCの中には複数のサブネットがあり、そのうちのいくつかはプライベートサブネットに分かれているものとします(個人的にはインターネットゲートウェイの有無しか違いがないので、プライベートサブネットあまり作りたくない)。
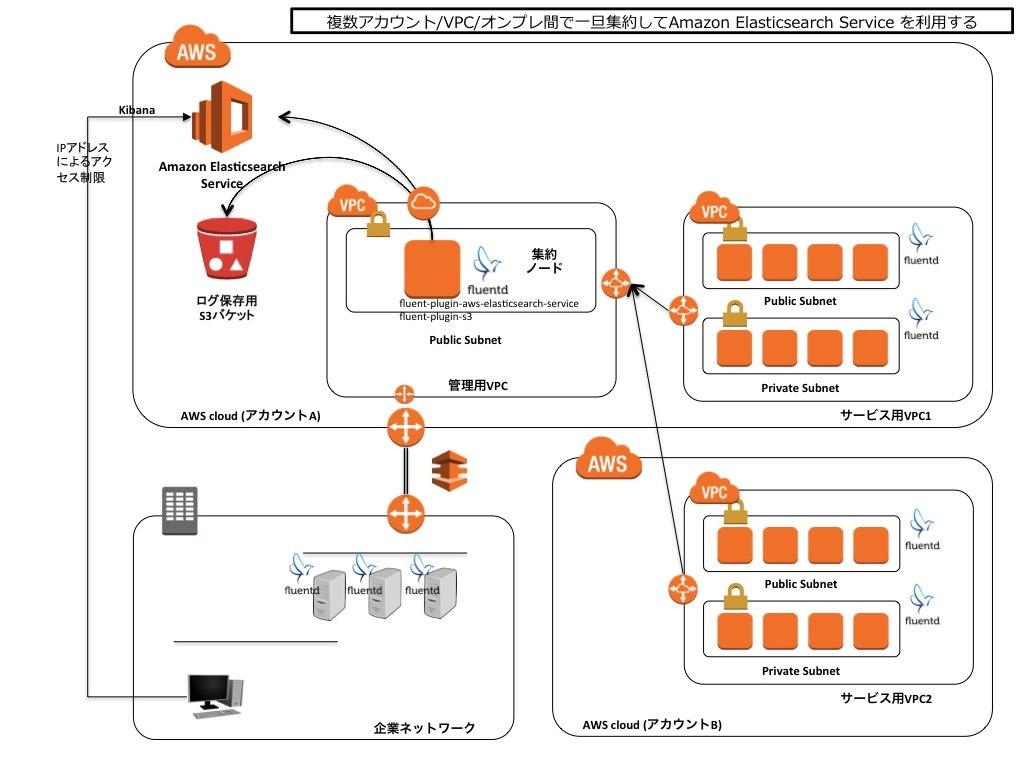
構成パターン1:FluentdのAggregatorを利用する
定番のログ集約用のAggregatorを用意する例。Amazon Elasticsearch ServiceはVPC外のサービスでアクセスするには、インターネットに繋がらないといけない(実際にはAWSの中で折り返し)ので、Aggregatorはパブリックサブネットに配置します。それぞれのVPCやアカウントとはVPCピアリングで直結し、AggregatorまではローカルIPでアクセスする形になります。 Aggregator側からAmazon Elasticsearch Serviceにデータを登録するためには、fluent-plugin-aws-elasticsearch-serviceプラグインを利用します。 またここで併せてログをS3に保存したければ、fluent-plugin-s3を併用すれば良いでしょう。
この構成のメリットは以下のとおりです。
- Aggregatorまでの転送は定番なやり方で、既存のやり方と大きく変える必要がない
- Elasticsearch側へのデータ反映までのタイムラグが少ない
- ネットワーク的な経路を迷う必要がない
- データ加工を色々やりたければ、ProcessorのノードをEC2で作ることもでき、このあたりも今までと変わらない
一方で以下の点については考慮が必要です。
- Aggregatorの可用性。複数台で構成することもできるが、EC2のインスタンスを自前で運用しないといけない
- EC2の料金のインパクト
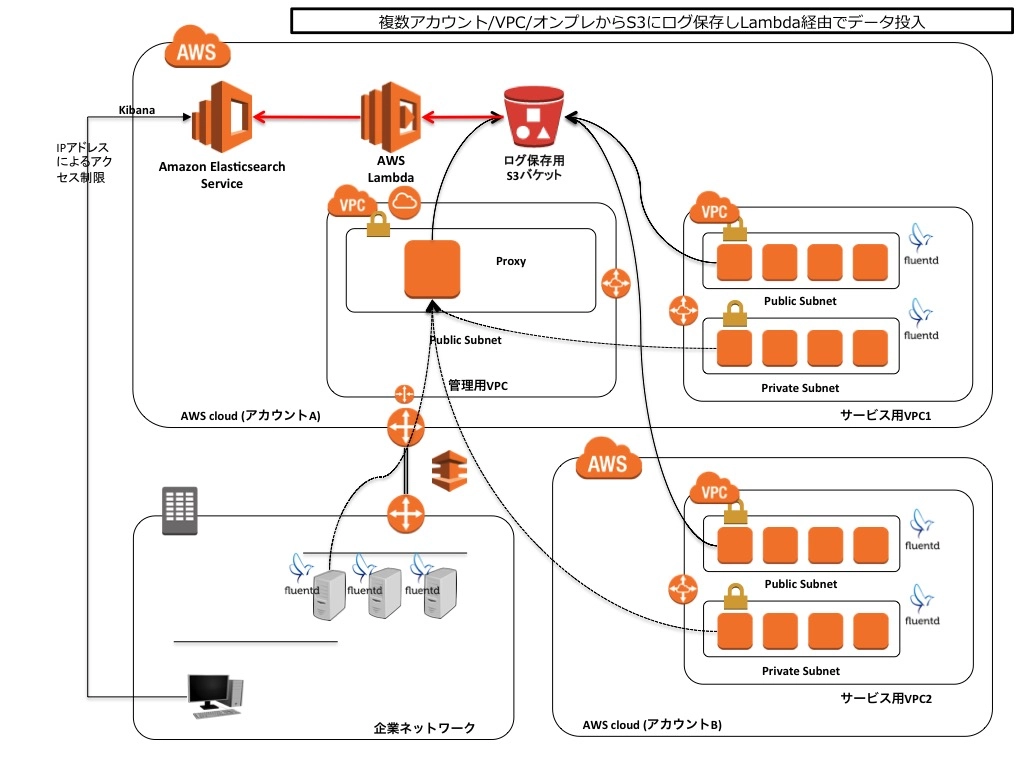
構成パターン2:S3 + Lambdaを利用する
こちらの例はEC2を使わずに実現する例。各サーバのFluentdでfluent-plugin-s3を利用し、指定したS3のバケットにログをためていきます。プライベートサブネットからの場合はプロキシを通します。 Lamdaでは、S3のバケットにファイルが作られたら、そのイベントをトリガーにしてLambda Functionを起動し、データをElasticsearch側に登録します。詳細なやり方についてはAWSのサイトでも紹介されています。
この構成のメリットは以下のとおりです。
- EC2がないので運用としては楽
- データ加工をしたい場合もLambdaである程度自由にできる
- S3のライフサイクルポリシーを使えば古いログを自動でアーカイブできる
一方で考慮点としては以下が挙げられます。
- 一旦S3にファイルを出力し、それをトリガーにするのでデータ反映までのタイムラグは多少増える(flush_intervalの設定による)
- flush_intervalを短く設定すると、大量のファイルがS3上に作られてしまう
- Lambdaのデバッグはちょっと面倒
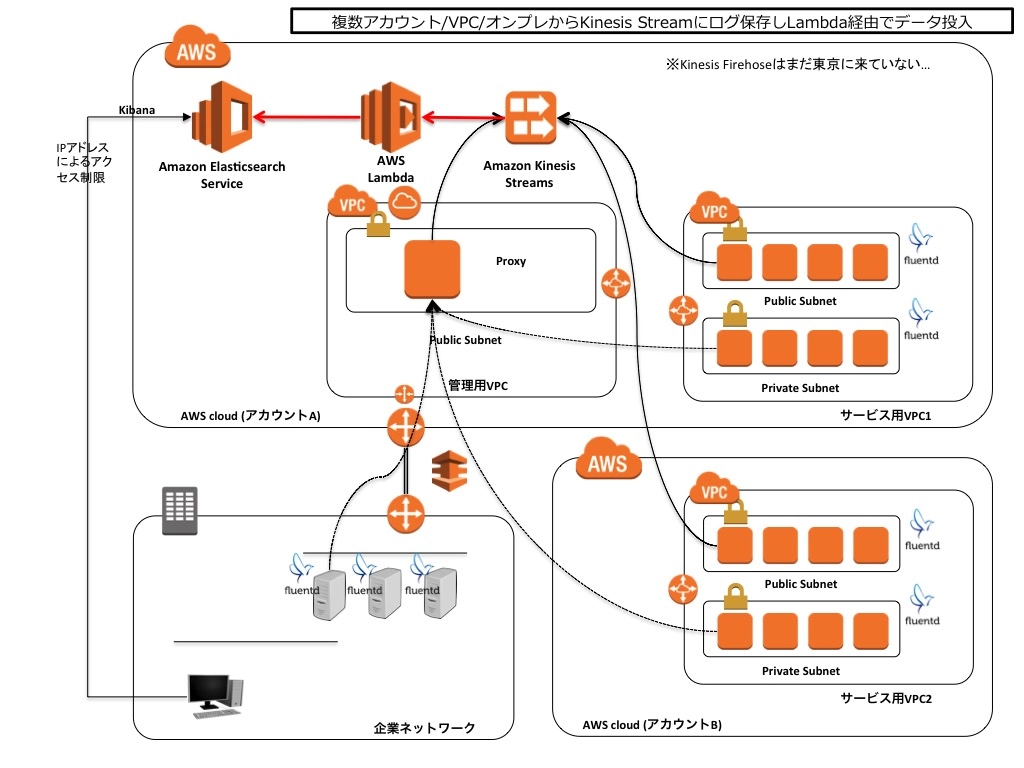
構成パターン3: Kinesis Streamsを利用する
Kinesis Streamsは、次々と送られてくる大量のデータをリアルタイムで集めてくれる土管のようなサービスです(Kinesis Firehoseは同じような感じでS3などにファイルを溜めてくれるサービスですが東京にはまだありません)。 各サーバからKinesis Streamsにログを送り続けて、そのデータをKinesis App(EC2上に実装)やLambdaを使って順番に処理していく形になります。 なお、fluentdのプラグインは、fluent-plugin-kinesisとなり、こちらもプロキシに対応しているので、プライベートサブネットからの場合はプロキシ経由にします。
この構成のメリットは以下のとおりです。
- Kinesis Streams自体が大量データのリアルタイム収集を目的として作られている
- したがって構成パターン2に比べてタイムラグを減らせる
- データの処理にLambdaを使う場合は、EC2が不要になり運用は楽
一方で考慮点としては以下が挙げられます。
- Kinesis AppをEC2上に作ると運用がめんどくさい
- Lambdaで作った場合は構成パターン2と同様にデバッグがちょっと面倒
- S3にも保存しておきたい場合は、別のやり方と併用する必要がある
まとめ
さてどれがいいでしょうねぇ…






































